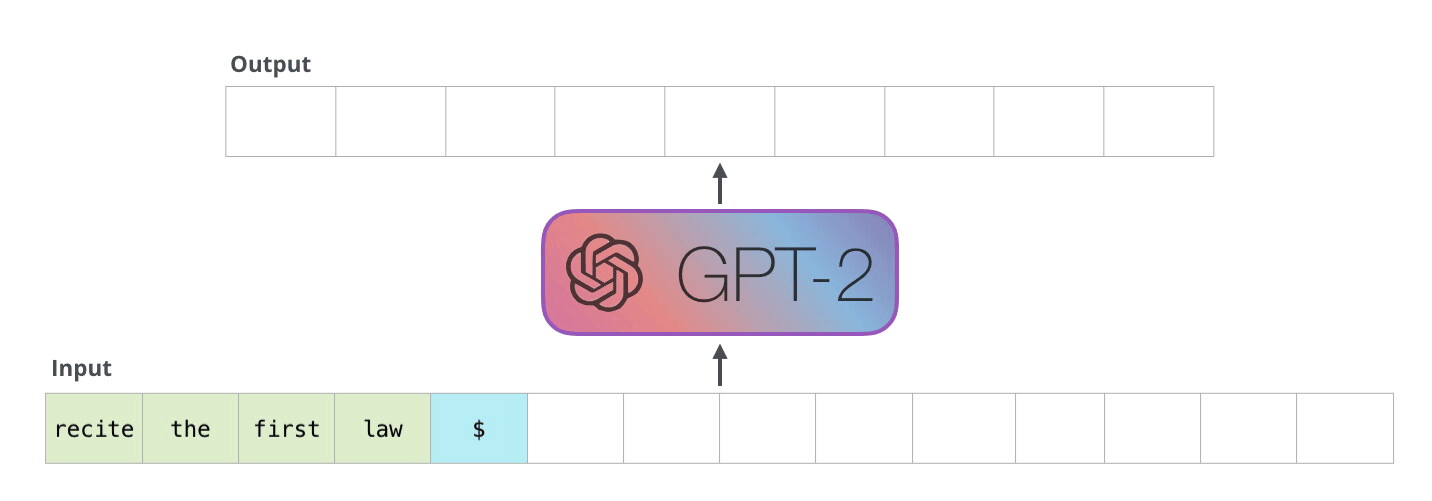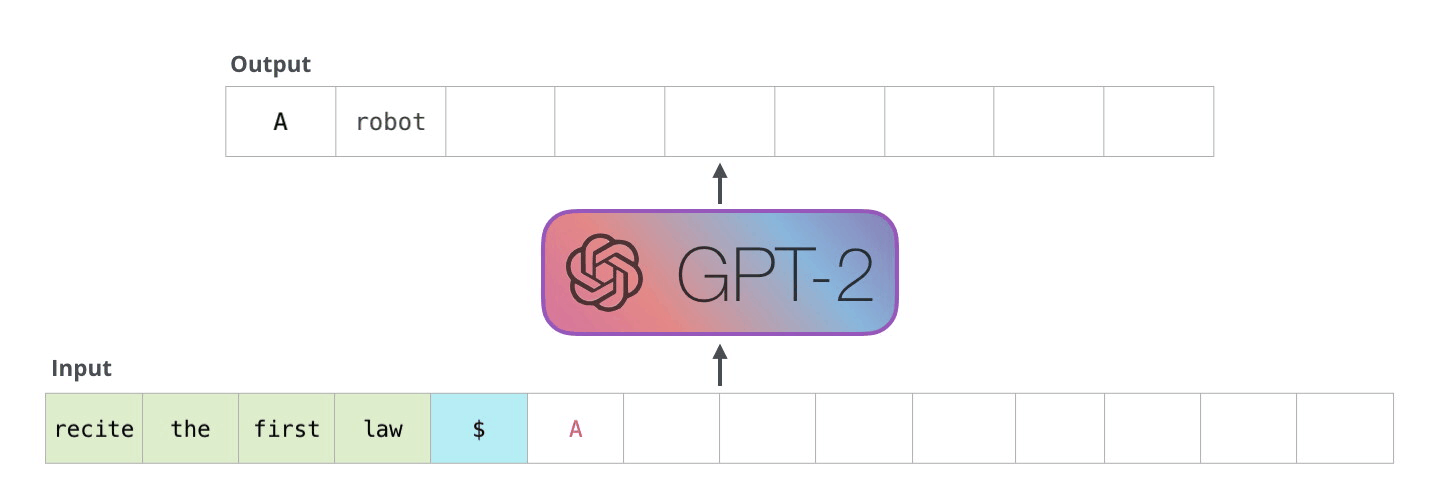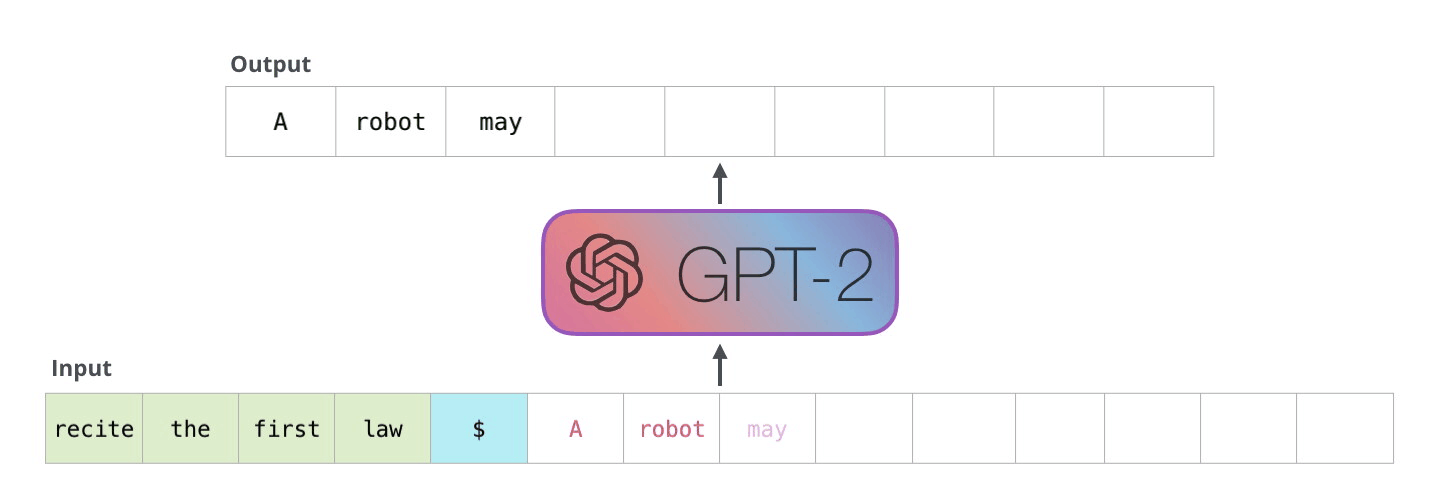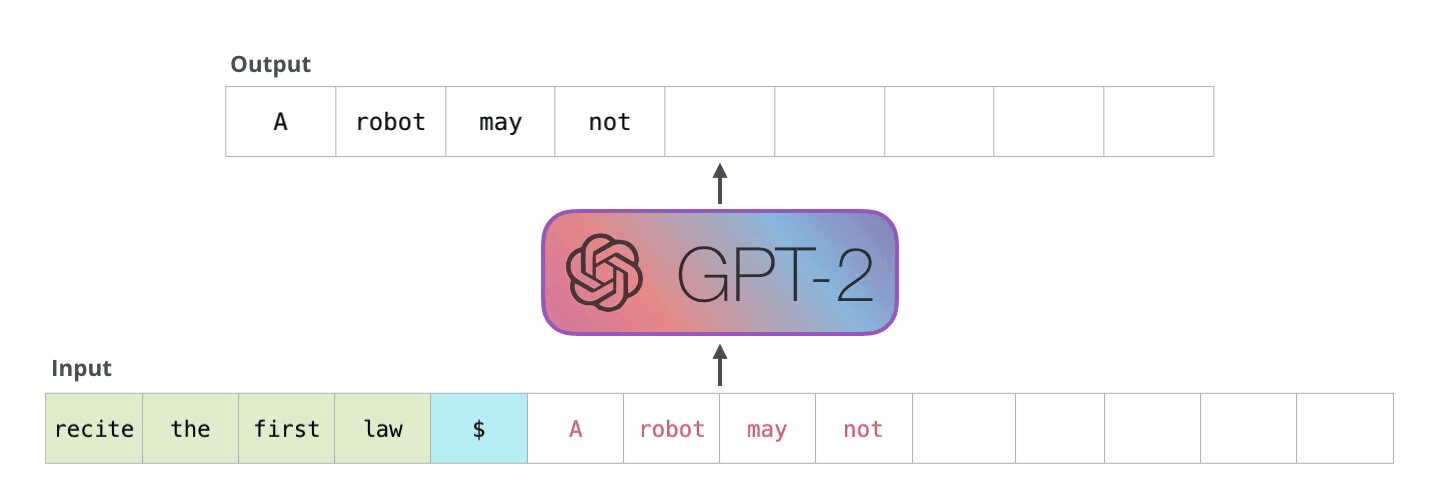
大模型推理过程
大模型的推理可以分为两个阶段:
- Prefill: 基于全部Prompt进行前向推理, 得到第一个token。计算密集。
- Decoding: 通过自回归方式, 递归输出新的token。内存密集。
由于 Prefill与Decoding对资源需求的差异, 一般对这两阶段分别进行优化。 KV Cache是针对Decoding阶段的优化, 有助于提升 TPOT(Time Per Output Token), 而对 TTFT(Time To First Token)无明显益处。

KV Cache的原理
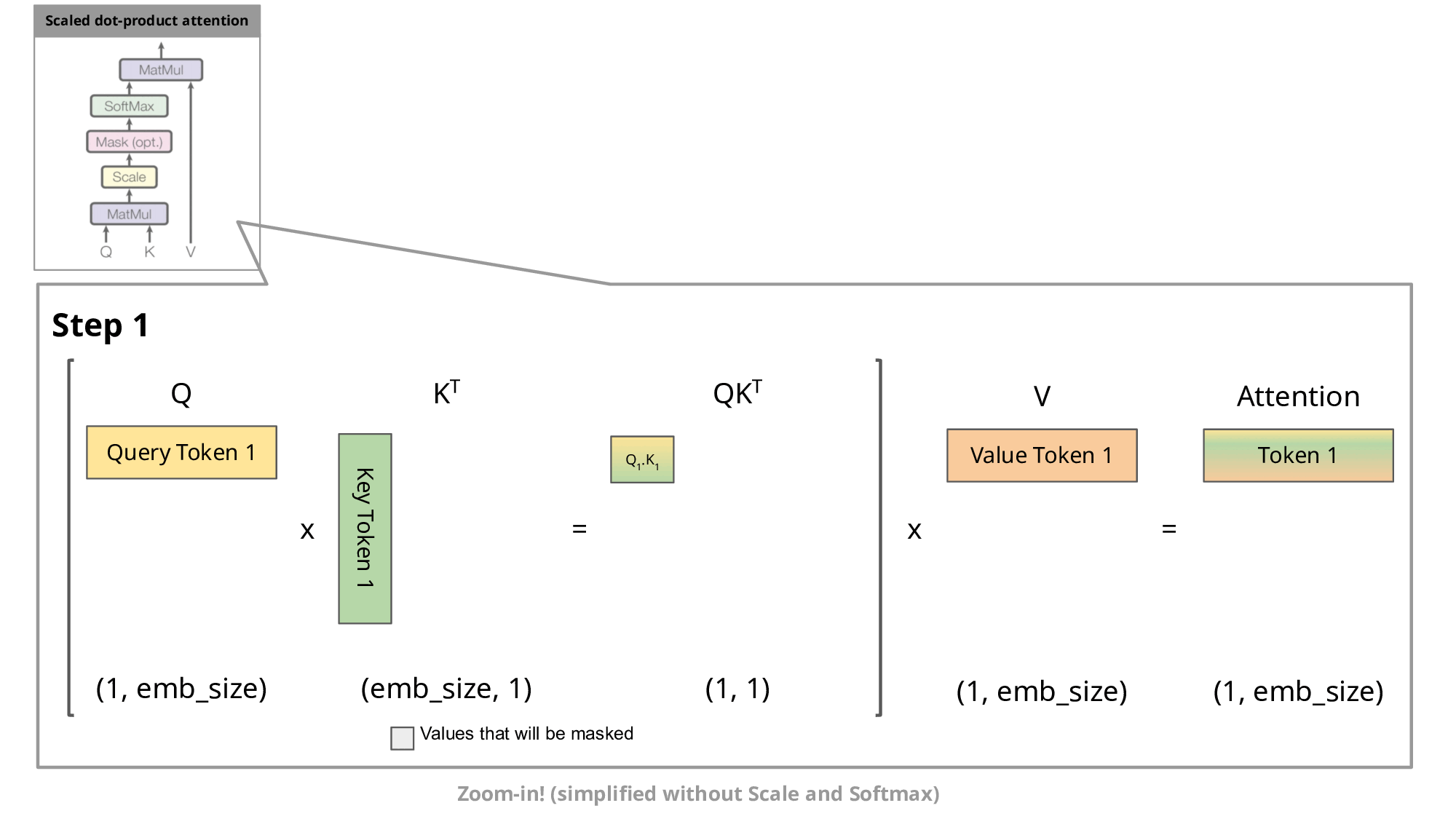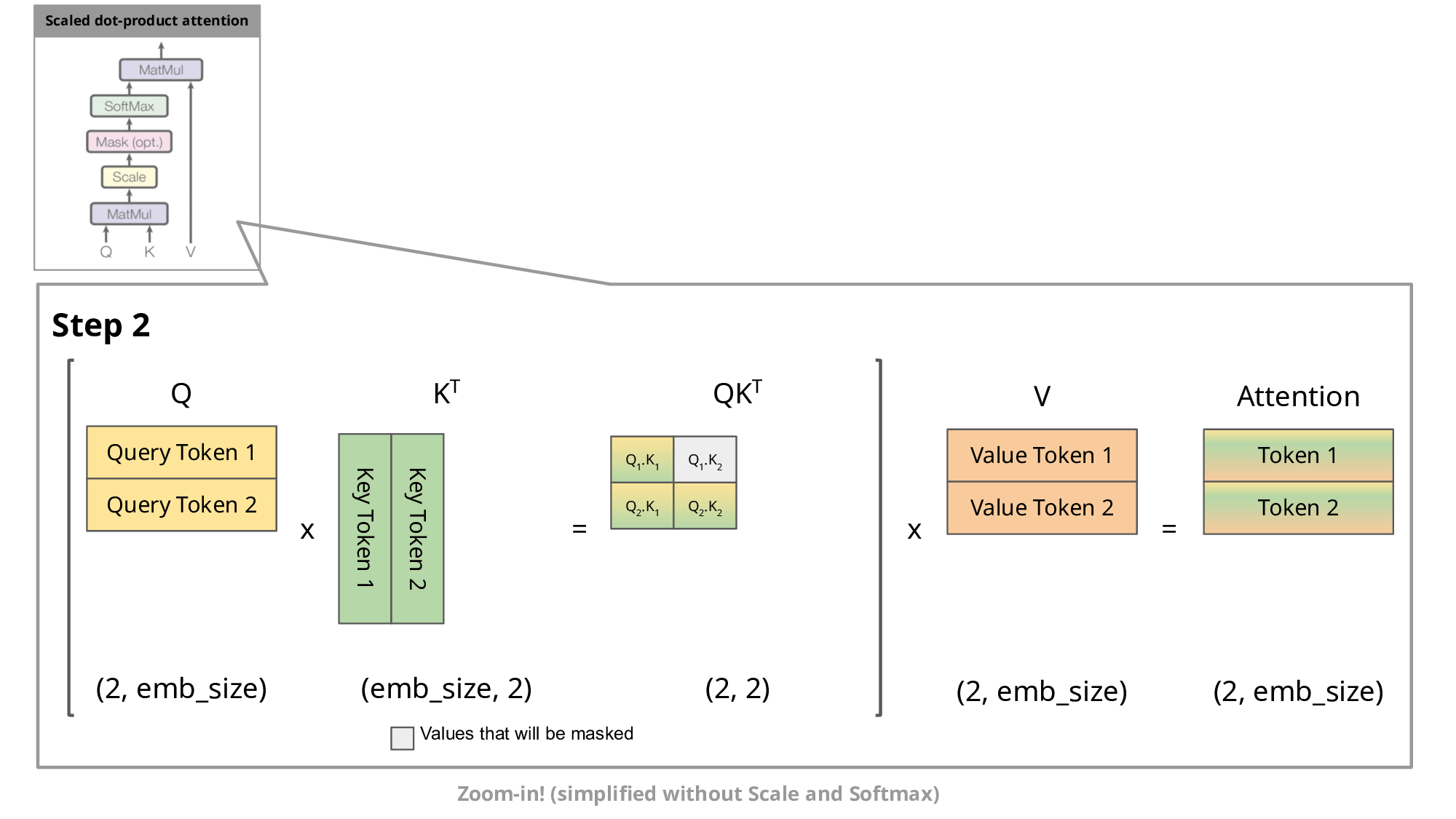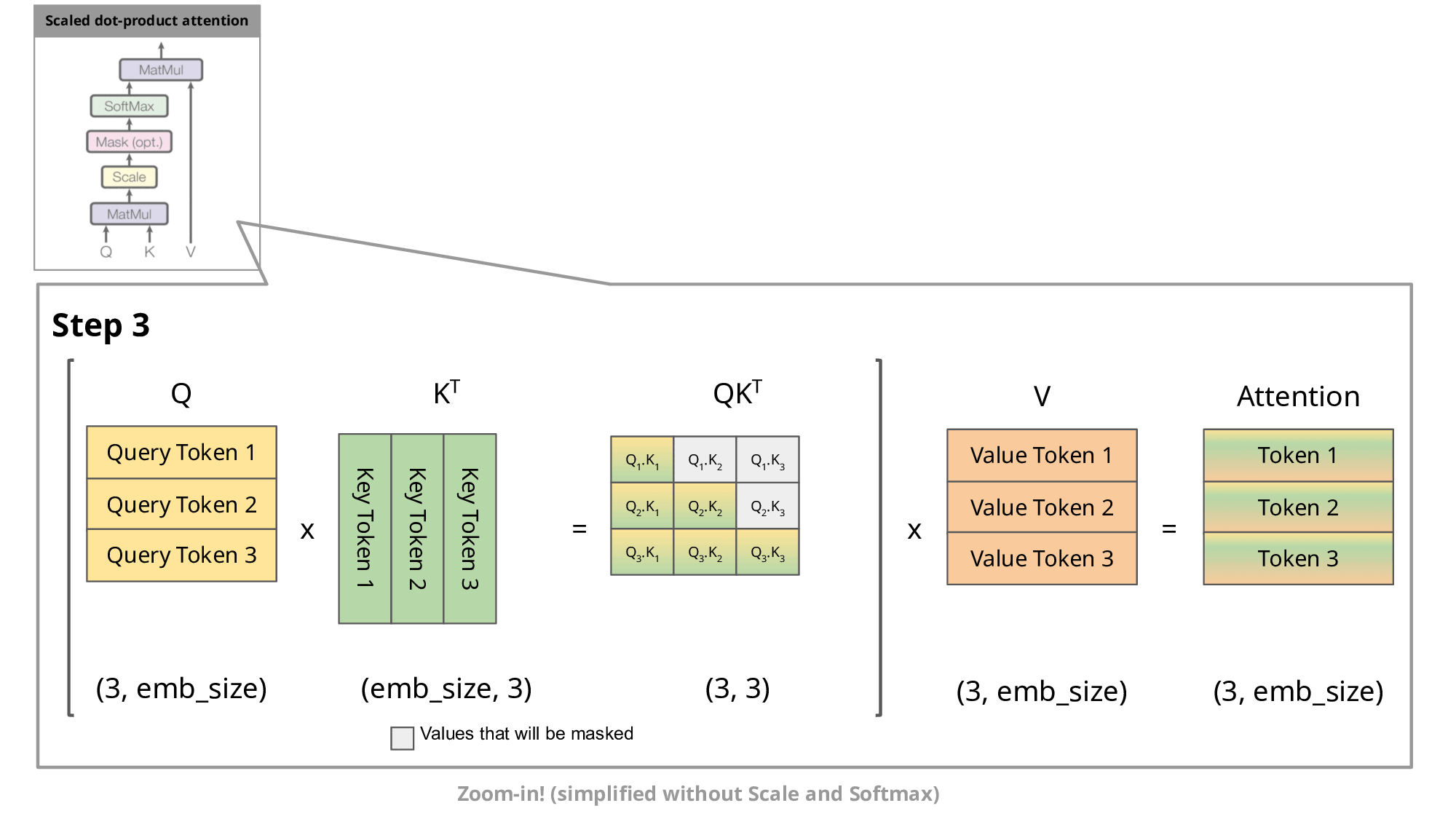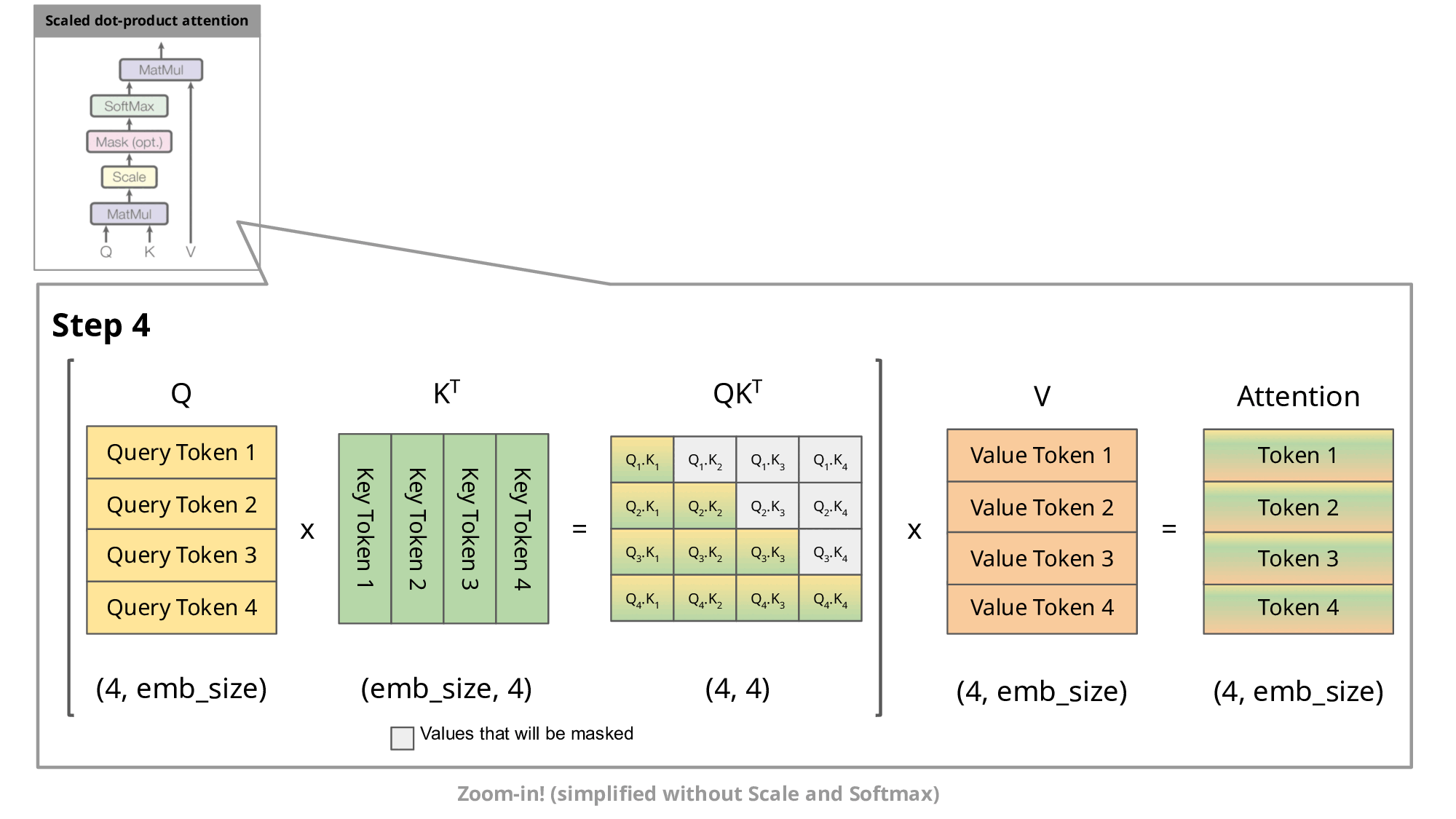
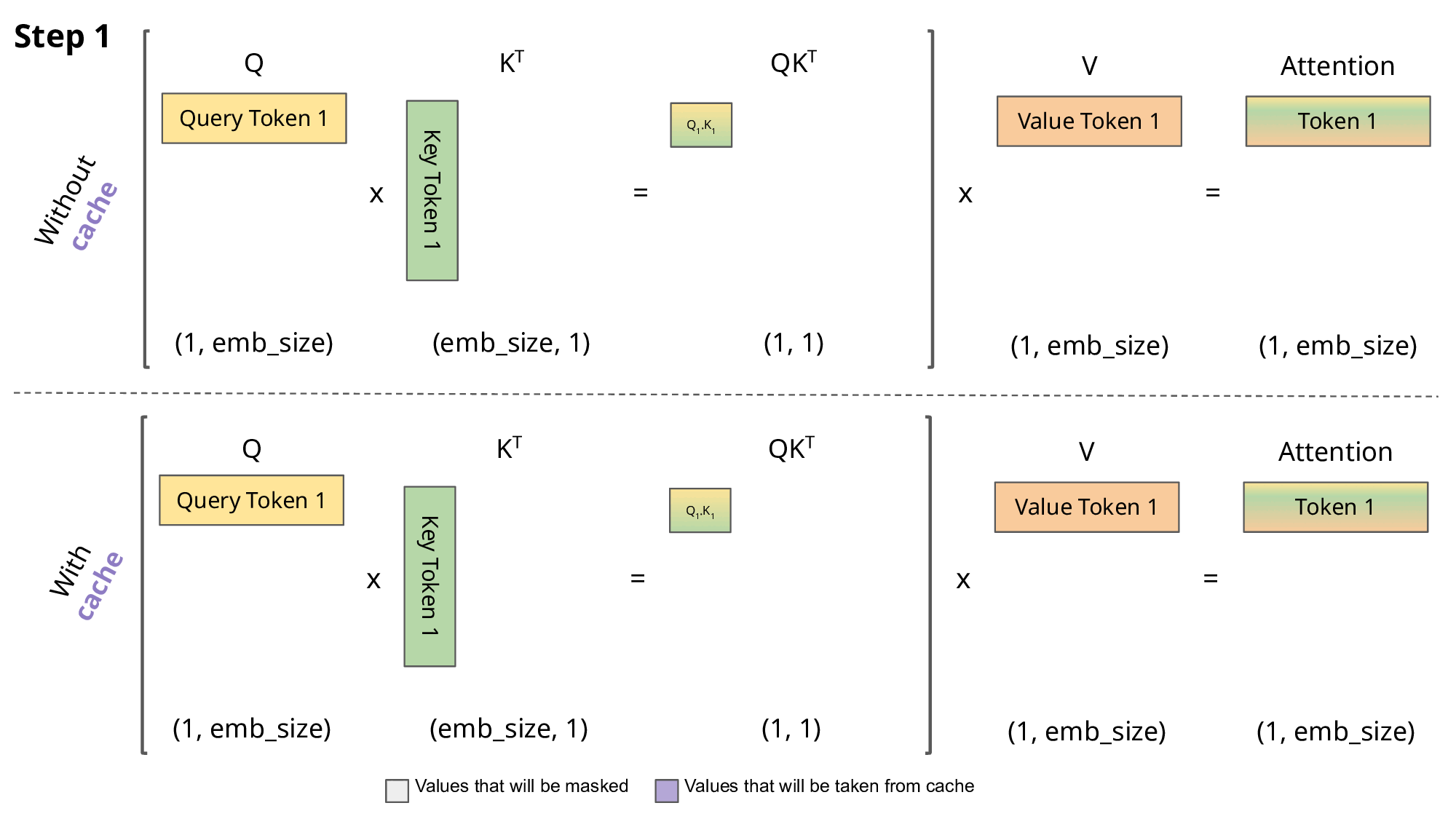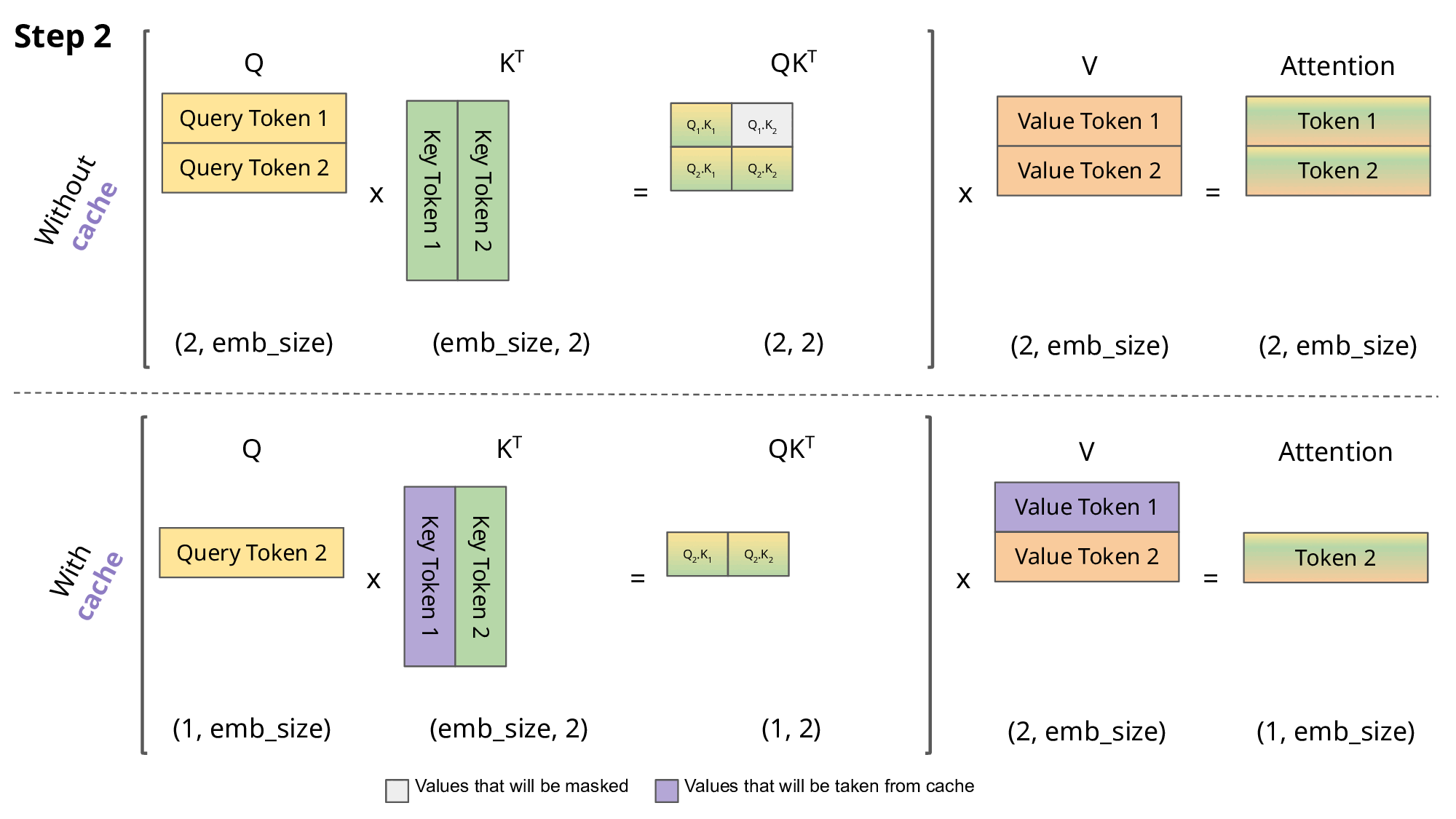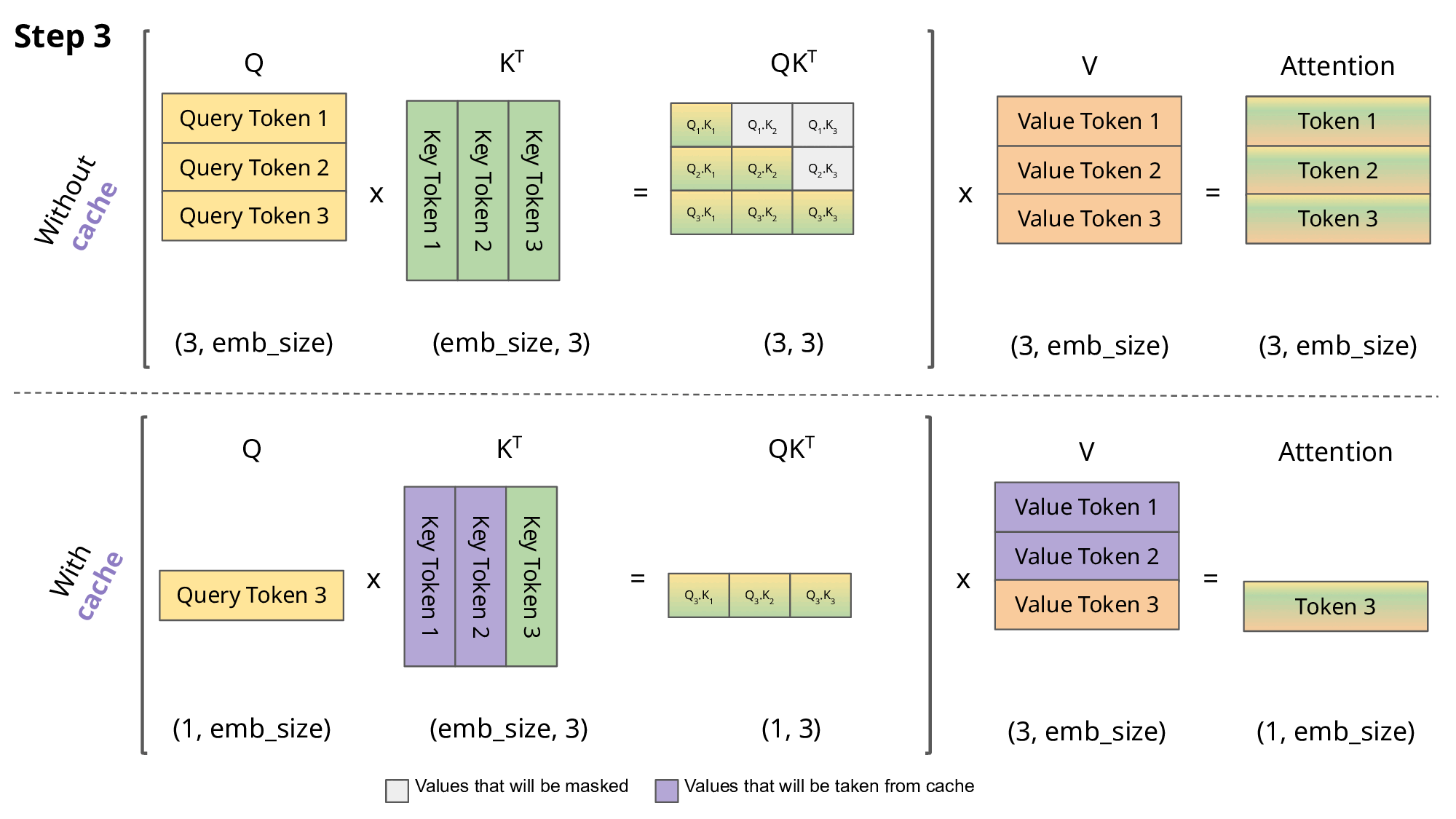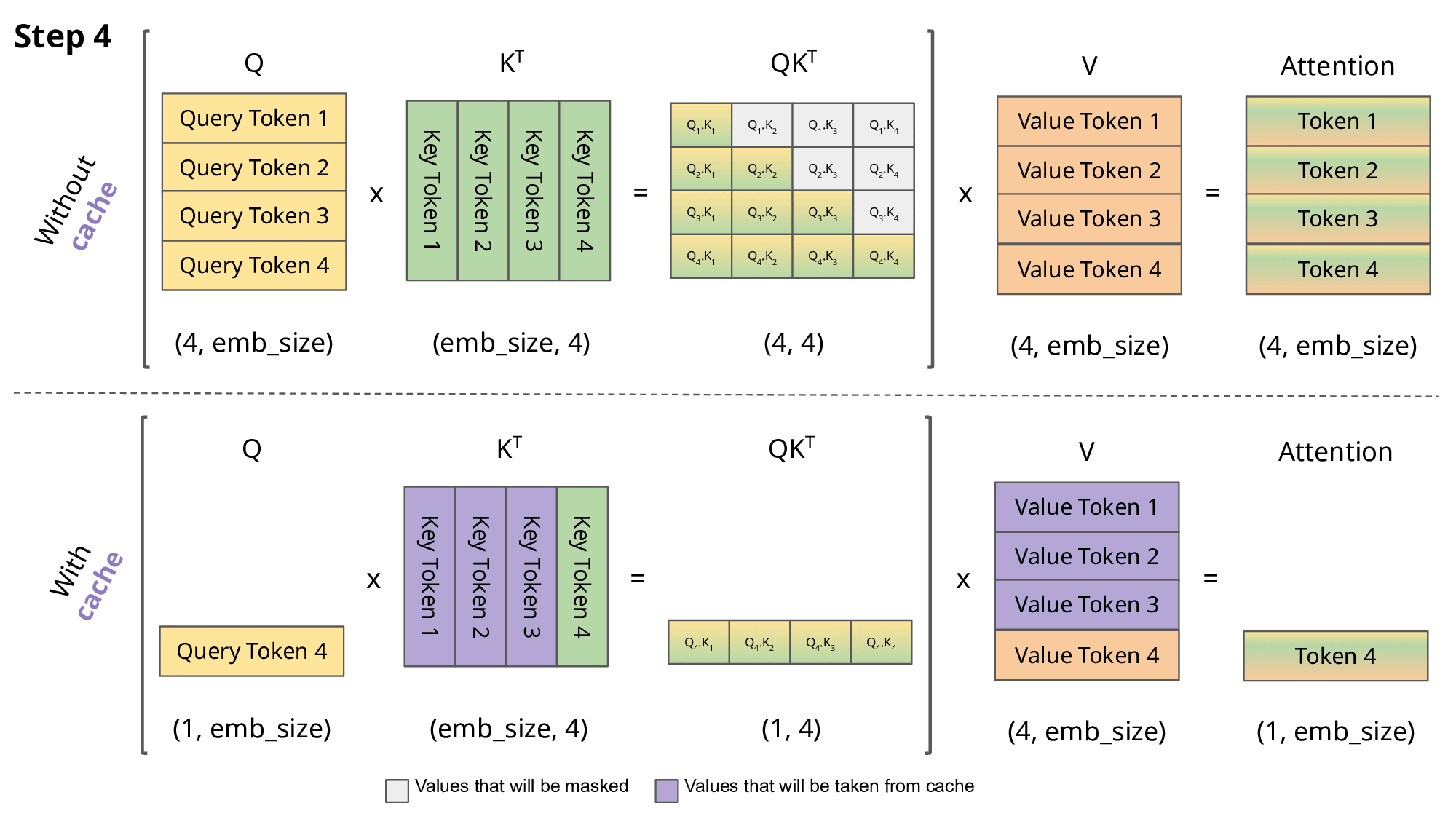
KV Caching是在推理Decoding阶段中的加速策略。 它基于自回归过程中对Attention计算过程中冗余性的观察。
由于 Decoder 是逐 Token进行输出的, 当前 Token的输出依赖于上一次 Token的输出。 而在每次生成新的 token时, 上一次得到的 K, V可以被重复利用。
因此 , 可以将之前计算的K, V矩阵进行缓存, 仅需要在当前步骤中,计算当前 token对应的K, V矩阵。
性能
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| import numpy as np
import time
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "distilgpt2"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint)
for use_cache in (True, False):
times = []
for _ in range(10):
start = time.time()
model.generate(**tokenizer("What is KV caching?", return_tensors="pt"),
use_cache=use_cache,
max_new_tokens=20)
times.append(time.time() - start)
print(f"TPOT {'with' if use_cache else 'without'} KV caching: "
f"{round(np.mean(times), 3)} +- {round(np.std(times), 3)} seconds")
for use_cache in (True, False):
times = []
for _ in range(10):
start = time.time()
model.generate(**tokenizer("What is KV caching?", return_tensors="pt"),
use_cache=use_cache,
max_new_tokens=1)
times.append(time.time() - start)
print(
f"TTFT {'with' if use_cache else 'without'} KV caching: "
f"{round(np.mean(times), 3)} +- {round(np.std(times), 3)} seconds")
|
KV Cache的代价
- GPU VRAM的占用
- 由于需要在内存中缓存K, V 矩阵, 导致VRAM被大量占用。这限制了最大序列长度和batch size。
- GPU会花费更多的时间在从缓存中加载数据上, 这限制了GPU的利用率。
- 很多大模型推理框架都从减少KV Cache的大小/降低KV Cache的碎片化/提升KV Cache的访存效率等角度出发来做系统的优化。
扩展
参考
[1] Transformers KV Caching Explained
[2] Unlocking Longer Generation with Key-Value Cache Quantization
[3] # 大模型推理加速与KV Cache(一):什么是KV Cache