2023年5月, 由Standford在论文 Direct Preference Optimization: Your Language Model is Secretly a Reward Model 中提出。 作为Reinforcement Learning from Human Feedback (RLHF) 的直接替代方案, DPO 不需要单独训练一个奖励模型, 也去除了冗余、耗时的人工标注环节, 因此在问世之后受到了极大的欢迎 。
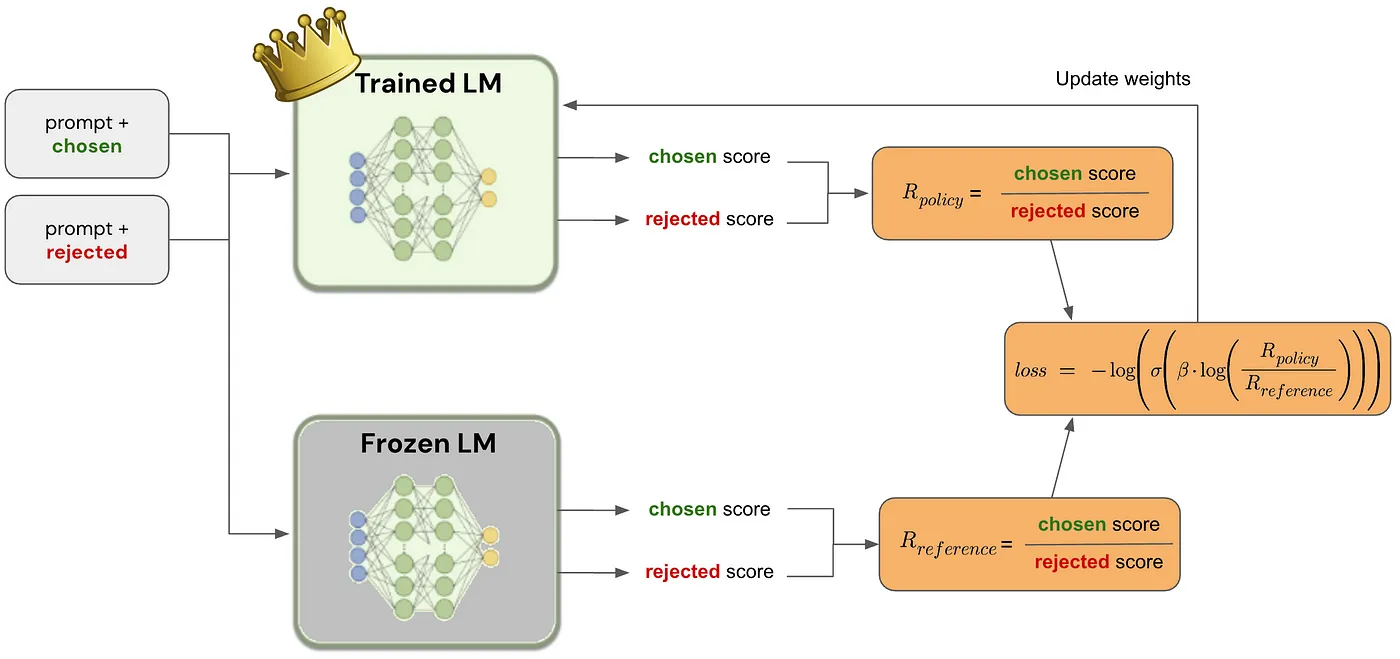
DPO 的数据输入格式如下:
1 | (prompt, chosen answer, rejected answer) |
与RHLF不同的是, 数据集不必基于当前模型的输出构造。
在微调开始时, 当前LM被复制一份, 并冻结其参数。 因此, 我们有两个模型, 一个是可训练模型(TLM), 一个是冻结参数模型(FLM)。
对于每一条输入样本, TLM和FLM分别对 chosen answer 和 rejected answer 进行打分。 打分由期望输出文本各个token的概率乘积得到 (做对数处理,否则会因精度溢出导致数值不稳定)。

得到这4个分数后, 就可以计算loss并用来更新 TLM了。

其中, $\beta$是超参数,用来控制TLM与FLM的偏离度(在Zephyr 中, $\beta$ = 0.1)。
DPO的优点: 稳定、高效、轻量。

这个公式来源于论文, 与上面简化版的公式是等价的。