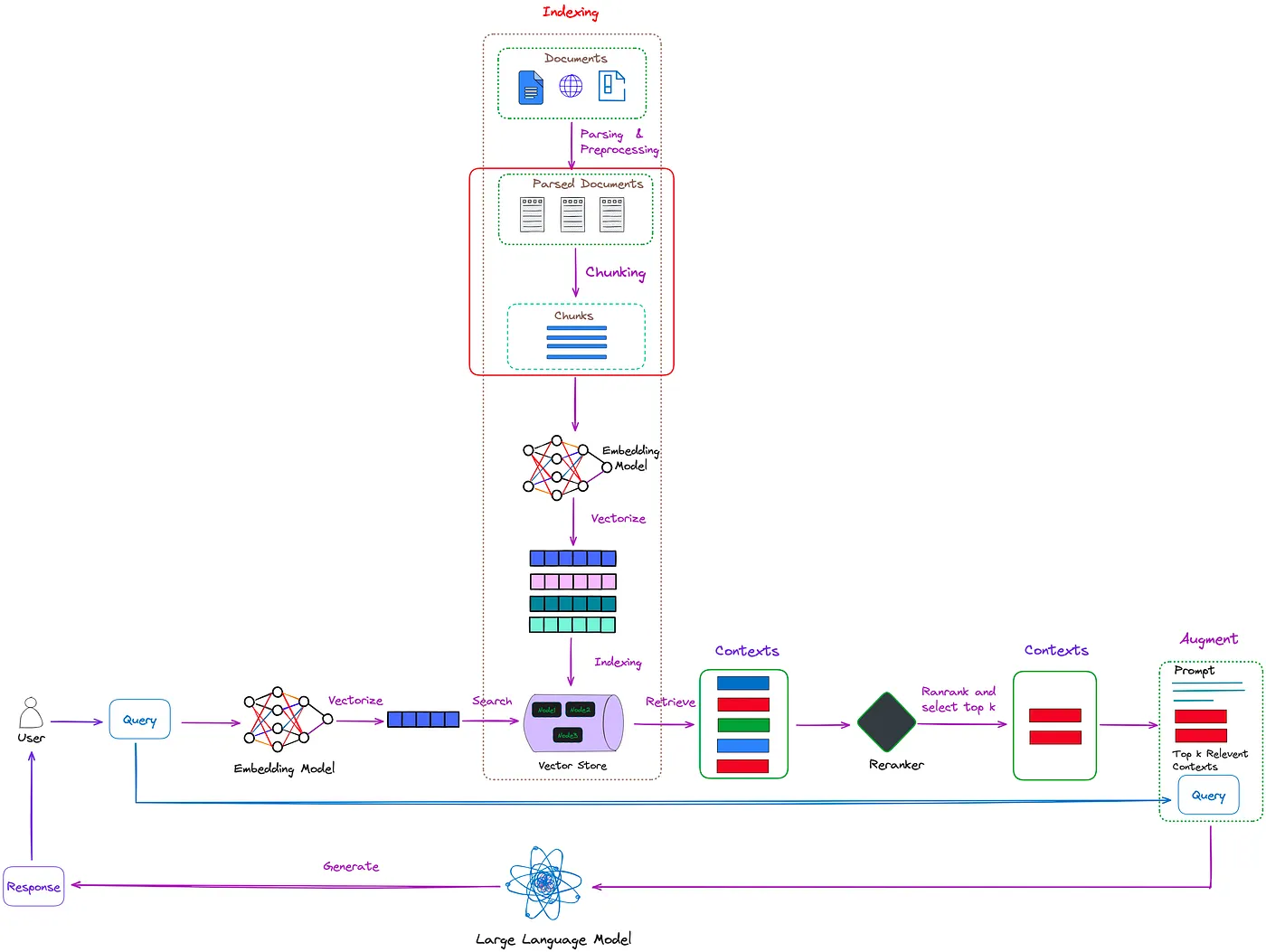
chunker = TokenChunker( tokenizer="gpt2", # Supports string identifiers chunk_size=16, # Maximum tokens per chunk chunk_overlap=4# Overlap between chunks )
text = """In Chinese mythology, there are five islands in the Bohai Sea, inhabited by immortal beings who have discovered the elixir of life. Many have searched for the islands, but no one have yet found them. I came close, however, four years ago this very week, when I travelled deep into the Nevada desert, to go to Burning Man """
chunks = chunker(text) for i, chunk inenumerate(chunks): print(f"Chunk {i} ({chunk.token_count} tokens): \n{chunk.text}")
输出:
1 2 3 4 5 6 7 8 9 10 11 12
Chunk 0 (16 tokens): In Chinese mythology, there are five islands in the Bohai Sea, inhabited by Chunk 1 (16 tokens): Sea, inhabited by immortal beings who have discovered the elixir of life. Many Chunk 2 (16 tokens): of life. Many have searched for the islands, but no one have yet found Chunk 3 (16 tokens): one have yet found them. I came close, however, four years ago this Chunk 4 (16 tokens): four years ago this very week, when I travelled deep into the Nevada desert, Chunk 5 (10 tokens): the Nevada desert, to go to Burning Man
from typing importList from langchain_core.prompts import ChatPromptTemplate, FewShotChatMessagePromptTemplate from langchain_core.pydantic_v1 import BaseModel, Field from langchain_groq import ChatGroq
# Data model classGeneratePropositions(BaseModel): """List of all the propositions in a given document"""
propositions: List[str] = Field( description="List of propositions (factual, self-contained, and concise information)" )
# LLM with function call llm = ChatGroq(model="llama-3.1-70b-versatile", temperature=0) structured_llm= llm.with_structured_output(GeneratePropositions)
# Few shot prompting --- We can add more examples to make it good proposition_examples = [ {"document": "In 1969, Neil Armstrong became the first person to walk on the Moon during the Apollo 11 mission.", "propositions": "['Neil Armstrong was an astronaut.', 'Neil Armstrong walked on the Moon in 1969.', 'Neil Armstrong was the first person to walk on the Moon.', 'Neil Armstrong walked on the Moon during the Apollo 11 mission.', 'The Apollo 11 mission occurred in 1969.']" }, ]
# Prompt system = """Please break down the following text into simple, self-contained propositions. Ensure that each proposition meets the following criteria: 1. Express a Single Fact: Each proposition should state one specific fact or claim. 2. Be Understandable Without Context: The proposition should be self-contained, meaning it can be understood without needing additional context. 3. Use Full Names, Not Pronouns: Avoid pronouns or ambiguous references; use full entity names. 4. Include Relevant Dates/Qualifiers: If applicable, include necessary dates, times, and qualifiers to make the fact precise. 5. Contain One Subject-Predicate Relationship: Focus on a single subject and its corresponding action or attribute, without conjunctions or multiple clauses.""" prompt = ChatPromptTemplate.from_messages( [ ("system", system), few_shot_prompt, ("human", "{document}"), ] )
proposition_generator = prompt | structured_llm
这些独立陈述随后被输入LLM进行评价, 从accuracy, clarity, completeness, and conciseness多个维度进行打分。
# Data model classGradePropositions(BaseModel): """Grade a given proposition on accuracy, clarity, completeness, and conciseness"""
accuracy: int = Field( description="Rate from 1-10 based on how well the proposition reflects the original text." ) clarity: int = Field( description="Rate from 1-10 based on how easy it is to understand the proposition without additional context." )
completeness: int = Field( description="Rate from 1-10 based on whether the proposition includes necessary details (e.g., dates, qualifiers)." )
conciseness: int = Field( description="Rate from 1-10 based on whether the proposition is concise without losing important information." )
# LLM with function call llm = ChatGroq(model="llama-3.1-70b-versatile", temperature=0) structured_llm= llm.with_structured_output(GradePropositions)
# Prompt evaluation_prompt_template = """ Please evaluate the following proposition based on the criteria below: - **Accuracy**: Rate from 1-10 based on how well the proposition reflects the original text. - **Clarity**: Rate from 1-10 based on how easy it is to understand the proposition without additional context. - **Completeness**: Rate from 1-10 based on whether the proposition includes necessary details (e.g., dates, qualifiers). - **Conciseness**: Rate from 1-10 based on whether the proposition is concise without losing important information. Example: Docs: In 1969, Neil Armstrong became the first person to walk on the Moon during the Apollo 11 mission. Propositons_1: Neil Armstrong was an astronaut. Evaluation_1: "accuracy": 10, "clarity": 10, "completeness": 10, "conciseness": 10 Propositons_2: Neil Armstrong walked on the Moon in 1969. Evaluation_3: "accuracy": 10, "clarity": 10, "completeness": 10, "conciseness": 10 Propositons_3: Neil Armstrong was the first person to walk on the Moon. Evaluation_3: "accuracy": 10, "clarity": 10, "completeness": 10, "conciseness": 10 Propositons_4: Neil Armstrong walked on the Moon during the Apollo 11 mission. Evaluation_4: "accuracy": 10, "clarity": 10, "completeness": 10, "conciseness": 10 Propositons_5: The Apollo 11 mission occurred in 1969. Evaluation_5: "accuracy": 10, "clarity": 10, "completeness": 10, "conciseness": 10 Format: Proposition: "{proposition}" Original Text: "{original_text}" """ prompt = ChatPromptTemplate.from_messages( [ ("system", evaluation_prompt_template), ("human", "{proposition}, {original_text}"), ] )
# Function to evaluate proposition defevaluate_proposition(proposition, original_text): response = proposition_evaluator.invoke({"proposition": proposition, "original_text": original_text}) # Parse the response to extract scores scores = {"accuracy": response.accuracy, "clarity": response.clarity, "completeness": response.completeness, "conciseness": response.conciseness} # Implement function to extract scores from the LLM response return scores
# Check if the proposition passes the quality check defpasses_quality_check(scores): for category, score in scores.items(): if score < thresholds[category]: returnFalse returnTrue
evaluated_propositions = [] # Store all the propositions from the document
# Loop through generated propositions and evaluate them for idx, proposition inenumerate(propositions): scores = evaluate_proposition(proposition.page_content, doc_splits[proposition.metadata['chunk_id'] - 1].page_content) if passes_quality_check(scores): # Proposition passes quality check, keep it evaluated_propositions.append(proposition) else: # Proposition fails, discard or flag for further review print(f"{idx+1}) Propostion: {proposition.page_content} \n Scores: {scores}") print("Fail")
保留下来的独立陈述经过Embedding模型进行编码进入索引。
1 2 3 4 5 6
# Add to vectorstore vectorstore_propositions = FAISS.from_documents(evaluated_propositions, embedding_model) retriever_propositions = vectorstore_propositions.as_retriever( search_type="similarity", search_kwargs={'k': 4}, # number of documents to retrieve )