Rewrite-Retrieval-Read 是由上海交大与微软亚洲研究院于2023年5月在论文(《Query Rewriting for Retrieval-Augmented Large Language Models》)[https://arxiv.org/abs/2305.14283]提出的一种RAG 查询优化策略。
与传统基于 Retrival + Read两步走的RAG架构不同, Rewrite-Retrieval-Read 增加了一个Query 改写环节(Rewrite), 通过LLM 对 Query进行改写, 从而提升检索环节的效果。
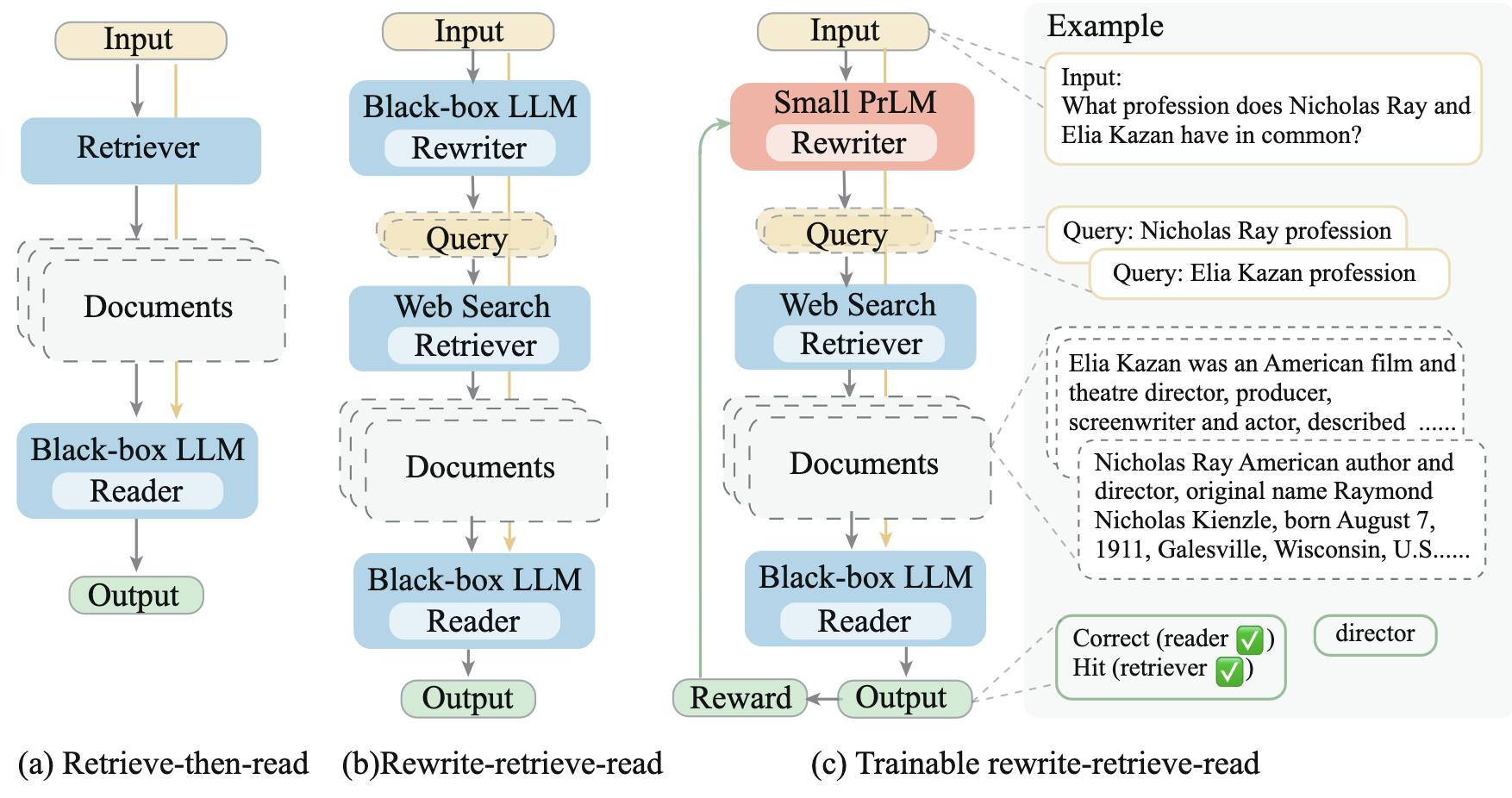
这个想法看着过于简单直接, 平平无奇,无法支撑论文的版面。 于是作者又提出了基于T5-large(770M)微调一个Query改写模型, 模型的训练分为两个阶段:
- 基于过滤后的LLM合成数据进行热启动训练。 训练目标为:
$$
\mathcal{L}{warm}=-\sum{t}\log p_{\theta}(\hat{\tilde{x}}{t}|\ \tilde{x}{<t},x)
$$ - 通过基于PPO的强化学习算法对Query改写模型进行对齐。 奖赏函数为:
$$
R(s_{t},a_{t}) = R_{lm}(\hat{\tilde{x}},y)-\beta\text{KL}(\pi_{\theta}||\pi_{0})
$$
最终的损失函数由策略损失和价值损失的加权和构成:
$$
\begin{align*}
\mathcal{L}{\theta}&=-\frac{1}{|\mathcal{S}|T}\sum{\tau\in\mathcal{S}}\sum_{t = 0}^{T}\min(k_{t,\theta}A^{\theta’}, \text{clip }A^{\theta’})
\mathcal{L}{\phi}&=\frac{1}{|\mathcal{S}|T}\sum{\tau\in\mathcal{S}}\sum_{t = 0}^{T}(V_{\phi}(s_{t})-R_{t})^{2},
\mathcal{L}{ppo}&=\mathcal{L}{\theta}+\lambda_{v}\mathcal{L}_{\phi}.
\end{align*}
$$
文章给人的整体感受是想法平平无奇, 为了撑版本又整了点不实用的花活。