Doc2Query 是由微软的Liang Wang等人于2023年3月在论文《Query2doc: Query Expansion with Large Language Models》 中提出的一种RAG Query改写技术。
其思想非常简单直接: 约定原始查询Query, Doc2Query 通过 few-shot prompting 的方式, 生成若干个能够回答原始查询的伪文档, 然后将这些伪文档拼接到原始查询中, 作为新的查询Query。
伪文档的生成提示词示例如下:

对于稀疏检索(如BM25), 拼接方式如下:
$$
q^{+} = \text{concat}({q} \times n, d’)
$$
由于伪文档的长度显著长于原始Query, 为防止原始Query的语义被淹没, 需要对原始查询进行加权。
对于稠密检索(如DPR), 拼接方式如下:
$$
$q^{+} = \text{concat}(q, [\text{SEP}], d’)$
$$
即, 新的Query是原始Query和伪文档的拼接。
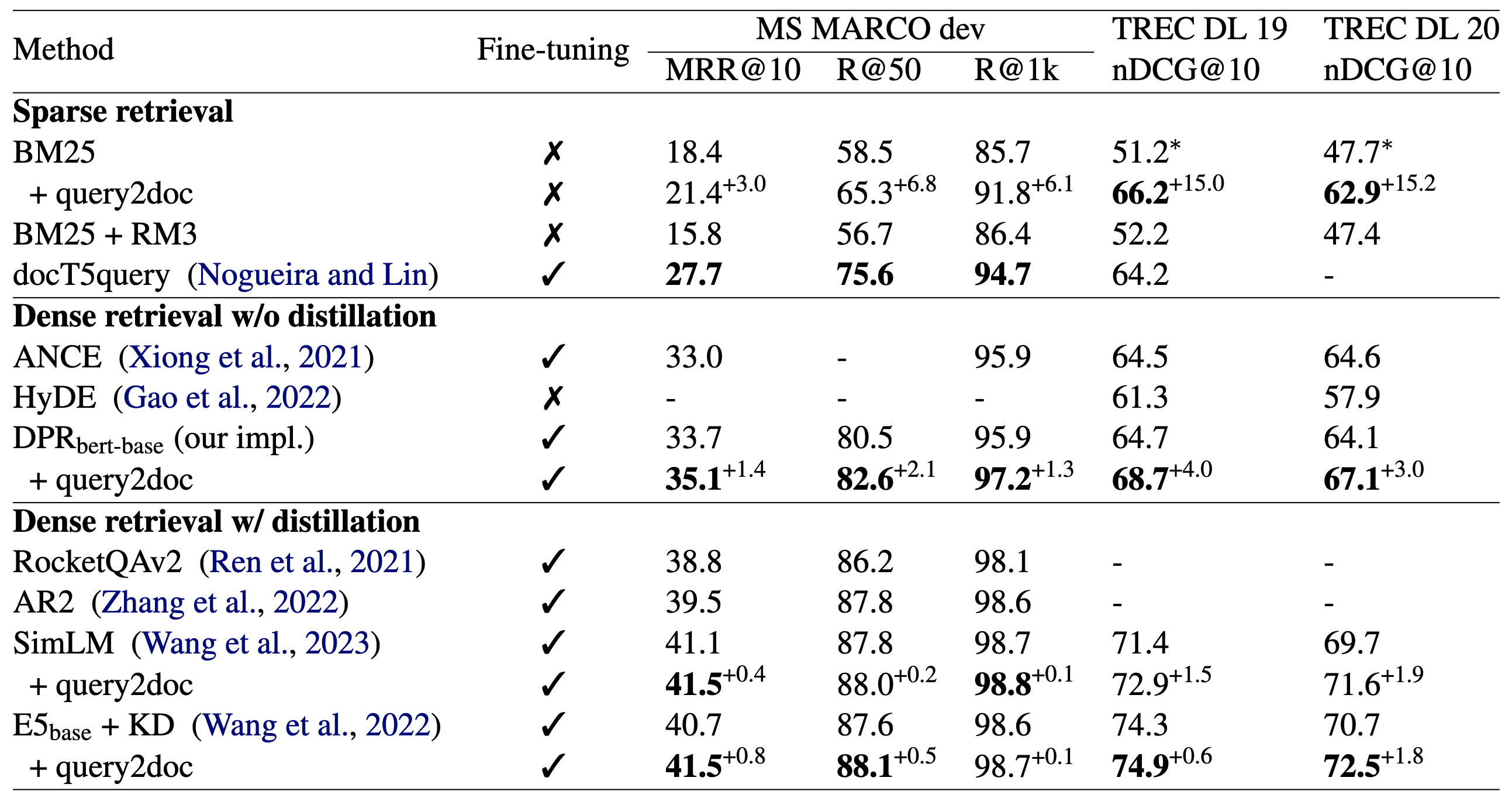
作者分别在领域内检索任务和零样本的跨领域检索任务下的不同数据集上进行了评估, 评估指标包括MRR@10, R@k ( k ∈ {50, 1k})以及 nDCG@10。 主要的实验结论如下:
对于领域内检索任务:
- 在稀疏检索任务中, BM25 + Doc2Query 的检索效果显著优于BM25 及 BM25 + RM3. (注: RM3是一种基于伪相关反馈的检索增强技术), 仅在部分数据上落后于 docT5query, 而 docT5query 的主要劣势是需要通过特定的数据集进行微调,成本较高。
- 在稠密检索任务中, DPR + Doc2Query 的检索效果显著优于 ANCE 和 HyDE。 但是, 与使用了中间预训练或是基于Reranker 蒸馏的方案, 如 RocketQAv2 和 AR2 相比, Doc2Query的优势并不明显。
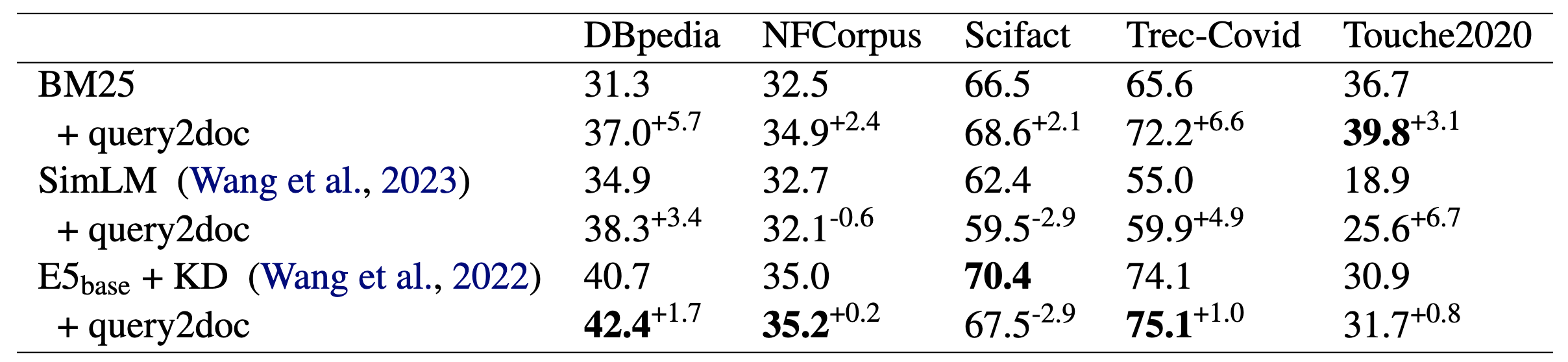
对于跨领域的零样本检索任务, Doc2Query 在DBPedia 上取得了显著的提升, 但在 NFCorpus 和 Scifact 数据集上, 其rank性能略有下降。 这可能与训练数据集与目标数据集的分布差异有关。
Doc2Query 是一种非常简单有效的RAG Query改写技术, 在思想上与 HyDE 非常相似, Psudo Document 即是 HyDE 中的 Hypothetical Document, 只是在拿到Psudo Document 后怎么得到最终的 Query的方案上略有不同。 Anyway, 在实践上都可以快速尝试, 毕竟几乎没有成本。